15-418/618 - Final Project Report
Swamynathan Siva and Andrew Zhao
In this project, we implemented an MSI directory-based cache coherence protocol and quantified the potential benefits from using an owner prediction algorithm to reduce shared memory access latency. The key idea is to predict which other caches share a given cache line and optimistically attempt to retrieve a copy of the shared line, and only consult the directory if the prediction is incorrect, with the hope of reducing indirection delay in successful cases. As secondary results, we measured the performance differences resulting from switching the cache coherence protocol from snooping MI to directory MSI. We discovered that adding a predictor resulted in significant speedups in terms of total program ticks, which was more pronounced in workloads with more dense data sharing, and that changing the protocol from snooping to directory resulted in a significant reduction in bus requests as expected.
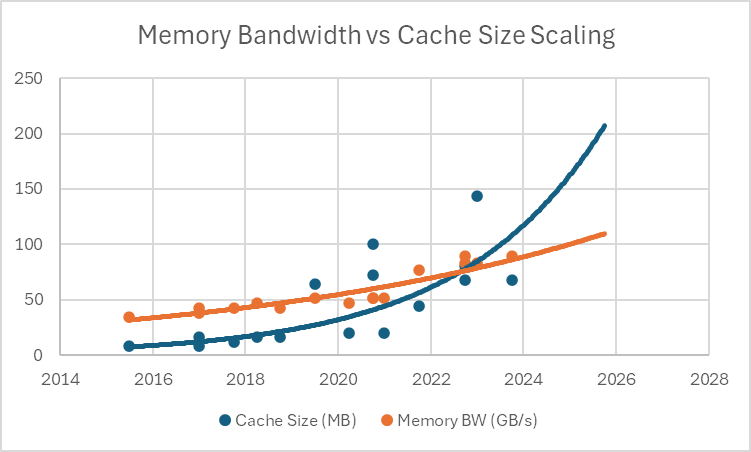
Cache coherence is an essential component to enable shared address space-based programming of parallel systems. Processors use caching to improve performance, and trends in memory scaling point to caching being increasingly indispensable. The figure below shows how memory bandwidth scaling has been almost linear (Moore’s law would expect it to be exponential), and so to compensate for that we can see that cache sizes have been growing exponentially in modern multicore processors. Physical design limitations and latency concerns encourage a strategy having a hierarchy - small, fast, private caches close to the processor that respond quickly for frequently accessed data, and larger, slower caches (that can be shared between all cores because they don’t have as strict area/latency limitations).
Memory bandwidth vs cache size over the past decade. Data points consist top-of-line Intel (Core i7/i9) and AMD (Ryzen 7/9) consumer chips for each generation
However the downside of caching, and specifically private caches, is that it can result in the same address (cache line) residing in multiple private caches simultaneously. This is fine when all copies of the line are just being read, but as soon as one of the processors writes to its copy of the line, it becomes ‘stale’ in the other caches and would create incorrect execution absent a mechanism to update or invalidate the copies. This is what cache coherence does - the basic purpose of a cache coherence system is to ensure that every processor has a consistent view of the memory system.
Initial implementations of coherence systems used snooping over a bus to handle coherence - anytime a processor wrote or accessed shared data it would broadcast that information to all the other processors and the memory controller, and depending on the state/presence of that address in their caches, they would respond accordingly, invalidate, writing back or sending the line. Predictably this does not scale well as more processing cores are added, as every shared memory from one of N processors operation results in N messages being sent, so the number of coherence messages scales as O(N^2).
Directory-based cache coherence was proposed to enable better scaling with increasing core counts. In this scheme, sharers and states are tracked by a unified directory. In a basic implementation, the directory is a hardware table that has as many entries as there are private cachelines, and each entry has a bit vector of which processor(s) currently have that cache line, and whether they have exclusive access. Now, every memory access to shared data goes through the directory, which serves as essentially a serialization point for producer-consumer shared memory communication. The directory performs the requisite actions to complete the request (invalidating, downgrading etc.) and replies to the processor with the data (for a read) or exclusive grant (for a write). As a result, many communications that were unnecessarily broadcasted in the snooping scheme are now point-to-point in the directory scheme, resulting in theoretically less network contention which is a primary bottleneck in scaling by core count.
However, the downside of directory-based schemes is that the directory access latency gets put into the critical path of any memory access on shared data. As cache sizes and chip areas (and hence NoC traversal distance in distributed directory architectures) scale, this latency becomes non-trivial. In addition, several workloads (such as producer-consumer workloads, ML Data Parallelism ringReduce etc.) have regular and predictable sharing patterns that have spatial and temporal locality that can be exploited to predict the outcome of a directory lookup. As such, we expect that an ownership predictor mechanism for shared reads in a directory, where shared reads attempt to circumvent the directory by predicting an owner of the data and issuing a point to point request and query the directory in the event of an incorrect prediction, may have significant benefits in reducing the latency introduced by a directory coherence system while maintaining its advantages over snooping systems. Academic literature has also evaluated this idea and found it to be promising [1] [2] [3].
Implementing the desired cache coherence system and measuring its effects as required of our project requires a computer architecture simulator. We based our work on the CADSS simulator, provided by Professor Railing, which provides a skeleton architecture simulator with simple initial implementations of several modules, along with binaries for reference ones. Of interest are the coherence, interconnect, and cache components; we decided that the scope of our project includes modifying the former 2 modules to implement directory-based MSI, and that we would use the most functionally complete cache that is compatible with our implementations. We chose not to use any of the reference binaries for any of our components - as we did not have the code for the reference implementations, and it became harder to reason and debug our work, and as such, the provided components ensure that the program is fully limited by the memory subsystem because the front end and midcore are completely not simulated. We expect that being fully back-end bound takes noise from other system bottlenecks out of the picture and guarantees that any speedup or slowdown observed is entirely attributable to changes in the memory subsystem.
Our work on this project can be divided into three key steps. First, we modified CADSS to implement the MSI protocol and a directory scheme. Next, we added tooling to collect performance data and implemented a simulated predictor. Finally, we collected data comparing the performance using the several types of components we implemented.
The base simulator uses an MI protocol where only one processor holds the exclusive modified state at any given time. However, owner prediction’s benefits are limited without shared reads, and as such, an MI protocol is far from representative of modern systems. For shared reads, the goal is to correctly predict a single sharing processor from which to obtain a copy of the data, resulting in good potential for performance improvement.
As a result of the above observations, we implemented the MSI protocol to introduce a shared read state. The protocol logic follows the state diagram shown in lecture, with busRd/busRdX/Data messages triggering transitions of a given cache line between modified, shared, and invalid states. Race condition preventance was the primary design challenge; if 2 processors simultaneously receive RdX requests from their caches, there must be some form of arbitration to prevent a state with 2 caches holding a line as M. The implementation we used for this is to introduce intermediate transition stages for any state promotion. Upon receiving an exclusive read request from its cache, a line in the INVALID state will promote to INVALID_MODIFIED and spin in that state until it snoops a message from the current modifier. Since our snooping is implemented as a sequential broadcast, one of the waiting processors is guaranteed to be the first recipient.
Another challenge of implementing MSI was arbitration of DATA messages; in the MI protocol, when a processor requests to upgrade a cache line from the INVALID state, the data is sent to it by the single processor who currently has that line as MODIFIED. In MSI, if many processors hold the line in SHARED state, there either needs to be an arbitration mechanism or duplicate messages need to be ignored. For simplicity of implementation, we chose to allow all sharers to respond, and add logic to ignore duplicate DATA messages.
The benefits from owner prediction only apply to a directory based cache coherence scheme, since a snooping scheme essentially broadcasts messages to every processor, with every processor receiving every bus message. As CADSS provides a snooping implementation, we needed to implement a directory protocol ourselves. This was accomplished by modifying CADSS’ broadcasting mechanism; CADSS simulates snooping by looping through all processors and sending out a secondary snoop message for each bus request on the interconnect. We replaced this mechanism with logic to perform a directory lookup, by pulling the directory from the coherence component, along with adding the corresponding delays for performance simulation; the state transition logic of bus requests was largely preserved, and the swapping of the loop for a lookup results in a simulated point-to-point communication scheme.
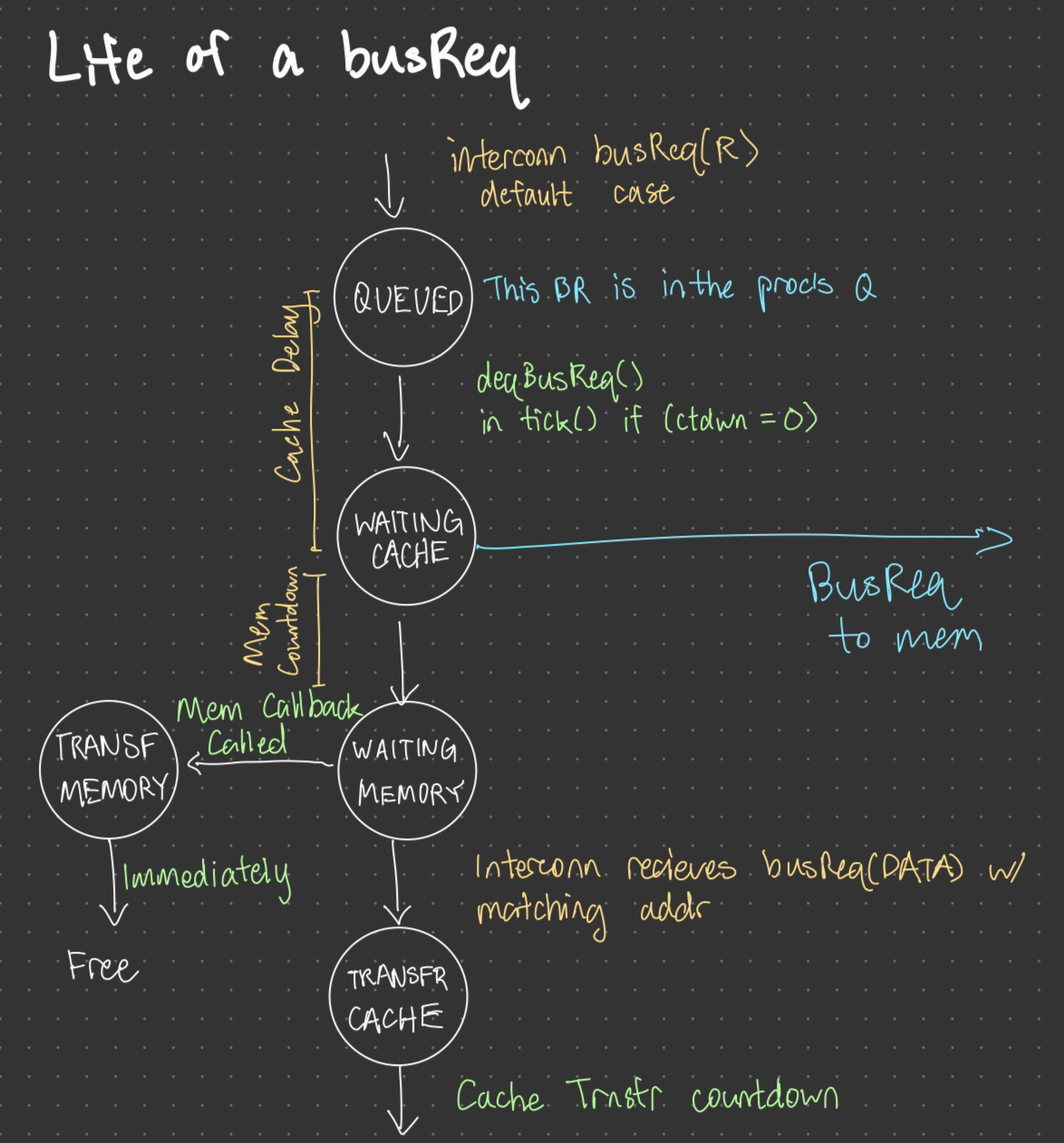
State Diagram for interconnect bus requests in CADSS. The cache delay will always occur, while the memory access delay can be interrupted by a snoop from another processor providing data.
Another important modification was to introduce directory delay, which is critical for getting correct performance measurements that are representative of reality. The base snooping implementation in CADSS implements all delays through a countdown in the stages of a BusRequest, which (1) waits several ticks as a cache delay, (2) sends a busRequest to memory and simultaneously performs snooping, and (3) waits out the memory access delay. We attempted to implement directory lookups on a timed delay, but ran into issues with correctness as CADSS makes assumptions that busRequests will happen instantly when they are called. To get around this, we added our directory delay as a fixed constant to the cache delay, and subtracted it from the memory access delay. As a result, successful directory accesses will be delayed by both the cache delay and directory delay as desired, while DRAM accesses will have the same measured results as before.
Three sets of comparisons arise from the systems we have implemented. In the following sections, we report data on each and provide a detailed discussion.
To evaluate the protocols, we chose 2 workloads which we predicted to have dense shared-mode data dependencies. First, we generated traces for the MPI Wireroute program from Assignment 4, with both 4 and 16 processors to investigate the effects of interconnect traffic. We picked the MPI version of WireRoute because the communication between processors was more explicit and hence easier to reason about - the primary communication in the implementation is the MPI ring-based allgather primitive. Here which processor a given processor sends data to and receives data from is very regular and fixed, meaning it would be easy to predict sharers in this case.
The second application we looked at was BFS from the Graph Algorithm Platform (GAP) benchmark suite [4], which uses OpenMP. We wanted a more standard application that used a shared memory model for our second choice, and BFS specifically seemed like a good choice because there would be a lot of read-based sharing, especially at the frontier, which could become very large in BFS. We generated traces for BFS search on a graph with 32K vertices and 5 starting sources.
The MI and MSI protocols in the snooping setting (with simpleCache, on 4-processor Wireroute) generate surprisingly similar results in total program ticks, snoop count, and bus request count. When examining the simulation debug printouts, we noticed that there was limited interleaving of accesses; one processor would make dozens of reads/writes consecutively, after which some bus requests would pass back and forth as access changed hands. As a result, the addition of a shared state did not have a significant impact on the observed metrics, because there was limited concurrent sharing of data to the point that other phenomena (limited simulation quality of cache and interconnect) dominated the results. The only anomalous result appears to be in a 16-core run of Wireroute (Wireroute_16), where MI appears to show a (~10%) performance improvement over MSI. Possible explanations in later sections after more in-depth data is presented.
The primary benefit of switching to a directory protocol is to reduce interconnect congestion by using point to point communication in place of a bus where possible. To quantify the improvement caused by switching to a directory, we measured the number of snoop messages sent per tick as a heuristic for network congestion (“snoop” referring to any message received by a processor from other sources). We observed that total program tick counts were very similar between directory and snooping implementations, so our analysis reduces to comparing total snoop counts. Our results show significantly fewer total snoops with the directory protocol as expected, in all 3 major workloads, with difference factors ranging from 3 to 8 times. This is expected, because the primary optimization of directory-based cache coherence is to perform a lookup and query only on processors that have the value cached for shared values, rather than broadcasting to everyone.
Of special note is that the 16 processor wireroute run reported <100 snoops per processor; this is likely because we ran a wireroute trace that had 16 wires, and accidentally happened upon a best case scenario. The 4-core wireroute shows a more realistic scenario, and with 16-core BFS we saw greatly reduced snoops in the presence of the high processor count of 16. This significant anomaly might also be why we saw a discrepancy between MI and MSI specifically in this workload in the previous set of results.
Adding and Evaluating Benefits of a Predictor
To evaluate the potential benefits of taking the directory access off the critical path of a memory access on different workloads, we modeled a simple probabilistic predictor. The predictor would flip a coin weighted by the simulated accuracy parameter, to determine if it was ‘correct’ and if so, take the directory access off the critical path of a memory request. If it was incorrect, and additional penalty was added to the request’s completion time. We chose both prediction benefit and misprediction penalty to be 60% of the cache latency (6 cycles), and performed sweeps over different predictor accuracies for the chosen workloads. Because of how our predictor is modeled, we see a break-even point around 50% accuracy in all the workloads, but it is interesting to see the wide range in potential benefit for between the configurations, with nearly a 4 fold difference in speedup between the worst application (Wireroute_16 - 5%) and the best (BFS 16- 22%). Again Wireroute_16 appears to be an outlier here because it has quite few occurrences of snoop requests because the number of cores matches the number of wires. BFS potentially shows the best benefit because of the high degree of data sharing between many cores (whereas in wireroute allgather, only two cores share any given piece of data). But for this reason, BFS might also be a tougher workload for a predictor.
Overall, we believe we have met all 100% targets we set for this project and begun exploring some stretch goals. Our MSI implementation shows similar behavior to reference implementations, and our snooping implementation had the predicted effect in drastically reducing busRequest counts. Despite these earlier stages displaying relatively unpredictable behavior in terms of total program ticks, we observed that adding a perfect predictor resulted in measurable, and in some workloads, significant improvements to speedup as measured by total ticks executed. We were also able to pursue the additional goal of investigating effects of a probabilistic predictor, and obtained results in line with what we were expecting.
A significant barrier to progress throughout this project was the nature of the abstractions in CADSS. Coming into the project, we had hoped that since the system was divided into several modules (memory, cache, interconnect, etc…), we would be able to focus on developing the interconnect and coherence components as desired, without worrying too much about the others. We discovered the hard way that this wasn’t the case; errors caused by one module frequently showed up as assertion errors in other ones, with the result being that we needed to trace bugs throughout 3+ different components to figure out what was wrong. For example, after spending several days developing and testing the directory interconnect, we discovered that the default cache does not invoke the coherence component at all. In another instance, when we implemented MSI but not arbitration for sending shared data to a prospective reader, the issue of duplicate data messages sent by the coherence protocol manifested as an interconnect error that we were only able to solve after realizing the interconnect contains the logic to process such messages. There we also several non-standard coding conventions in the provided CADSS code, such as pointers being used as data, extensive global variable use and linked list next pointers left uninitialized (ostensibly relying on malloc to zero out allocated data) that were difficult to work around/account for because a reflexive assumption of errors was predicated on a different coding style.
1 Libo Huang, Zhiying Wang, Nong Xiao, Yongwen Wang, and Qiang Dou. 2014. Integrated Coherence Prediction: Towards Efficient Cache Coherence on NoC-Based Multicore Architectures. ACM Trans. Des. Autom. Electron. Syst. 19, 3, Article 24 (June 2014), 22 pages. https://doi.org/10.1145/2611756
2 Lai, An-Chow, and Babak Falsafi. “Memory Sharing Predictor: The Key to a Speculative Coherent DSM.” International Symposium on Computer Architecture: Proceedings of the 26th Annual International Symposium on Computer Architecture; 01-04 May 1999. IEEE Computer Society, 1999. 172–183. Web.
3 A. Kayi, O. Serres and T. El-Ghazawi, "Adaptive Cache Coherence Mechanisms with Producer–Consumer Sharing Optimization for Chip Multiprocessors," in IEEE Transactions on Computers, vol. 64, no. 2, pp. 316-328, Feb. 2015, doi: 10.1109/TC.2013.217.
keywords: {Protocols;Coherence;Bandwidth;Optimization;Radiation detectors;Multicore processing;Cache coherence;producer/consumer;chip multiprocessors (CMPs);adaptable architectures},
4 Scott Beamer, GAP Benchmark Suite, https://github.com/sbeamer/gapbs
Swamy:
Andrew:
Overall, we agree that the work was split evenly (50/50) throughout this project.